Machine learning is a field of artificial intelligence (AI) that is concerned with learning from data. Machine learning has three components:
Supervised learning: Fitting predictive models using data for which outcomes are available.
Unsupervised learning: Transforming and partitioning data where outcomes are not available.
Reinforcement learning: on-line learning in environments where not all events are observable. Reinforcement learning is frequently applied in robotics.
Posts on machine learning
In the following posts, machine learning is applied to solve problems using R.
In reinforcement learning, we are interested in identifying a policy that maximizes the obtained reward. Assuming a perfect model of the environment as a Markov decision process (MDPs), we can apply dynamic programming methods to solve reinforcement learning problems.
In this post, I present three dynamic programming algorithms that can be used in the context of MDPs. To make these concepts more understandable, I implemented the algorithms in the context of a gridworld, which is a popular example for demonstrating reinforcement learning.
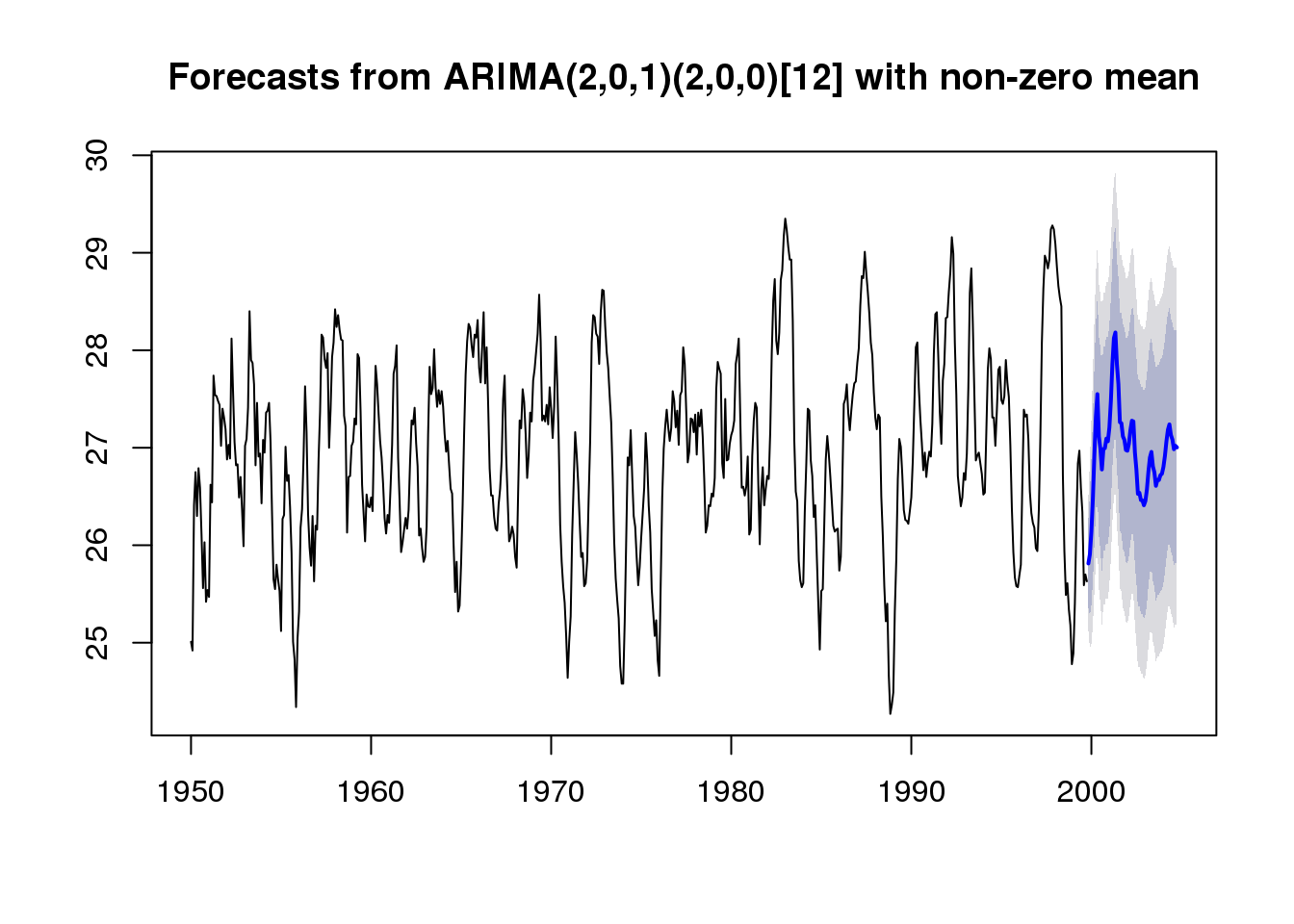
Forecasting is concerned with making predictions about future observations by relying on past measurements. In this article, I will give an introduction how ARMA, ARIMA (Box-Jenkins), SARIMA, and ARIMAX models can be used for forecasting given time-series data.
Preliminaries Before we can talk about models for time-series data, we have to introduce two concepts.
The backshift operator Given the time series \(y = \{y_1, y_2, \ldots \}\), the backshift operator (also called lag operator) is defined as
In supervised learning, we are often concerned with prediction. However, there is also the concept of forecasting. Here, I will discuss the differences between the two concepts so that we can answer the question why weather forecasting is not called weather prediction.
Predicion and forecasting Prediction is concerned with estimating the outcomes for unseen data. For this purpose, you fit a model to a training data set, which results in an estimator \(\hat{f}(x)\) that can make predictions for new samples \(x\).
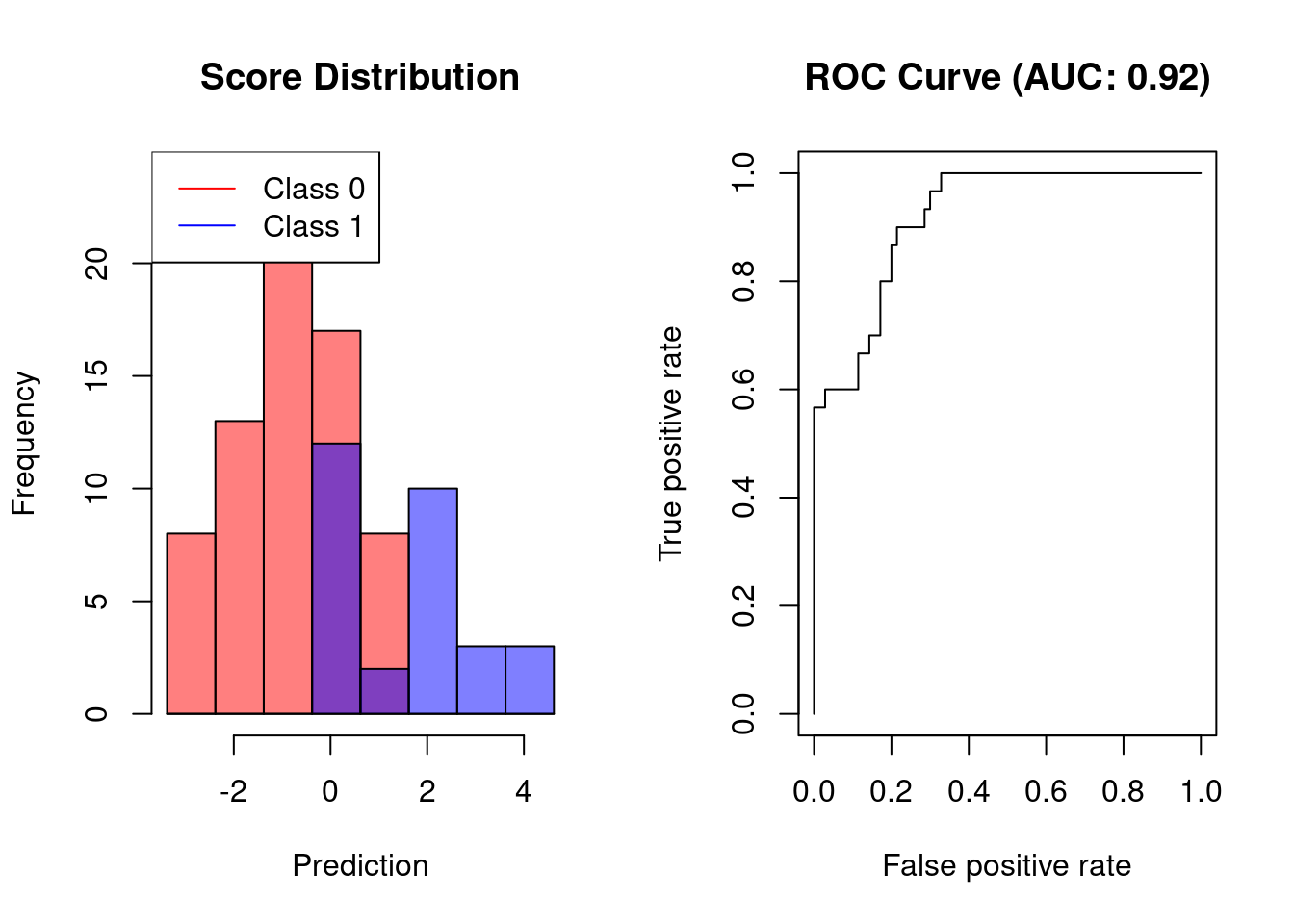
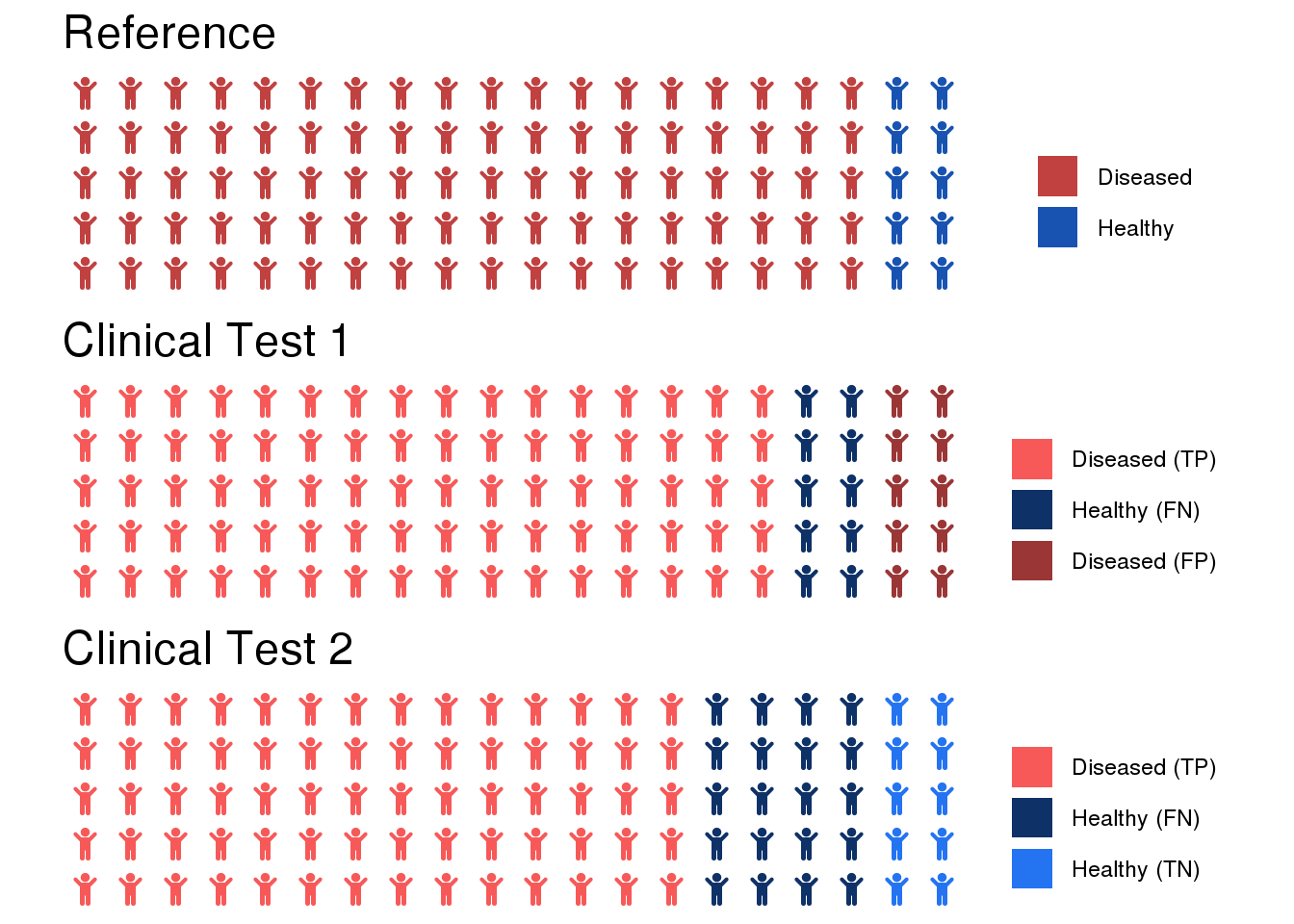
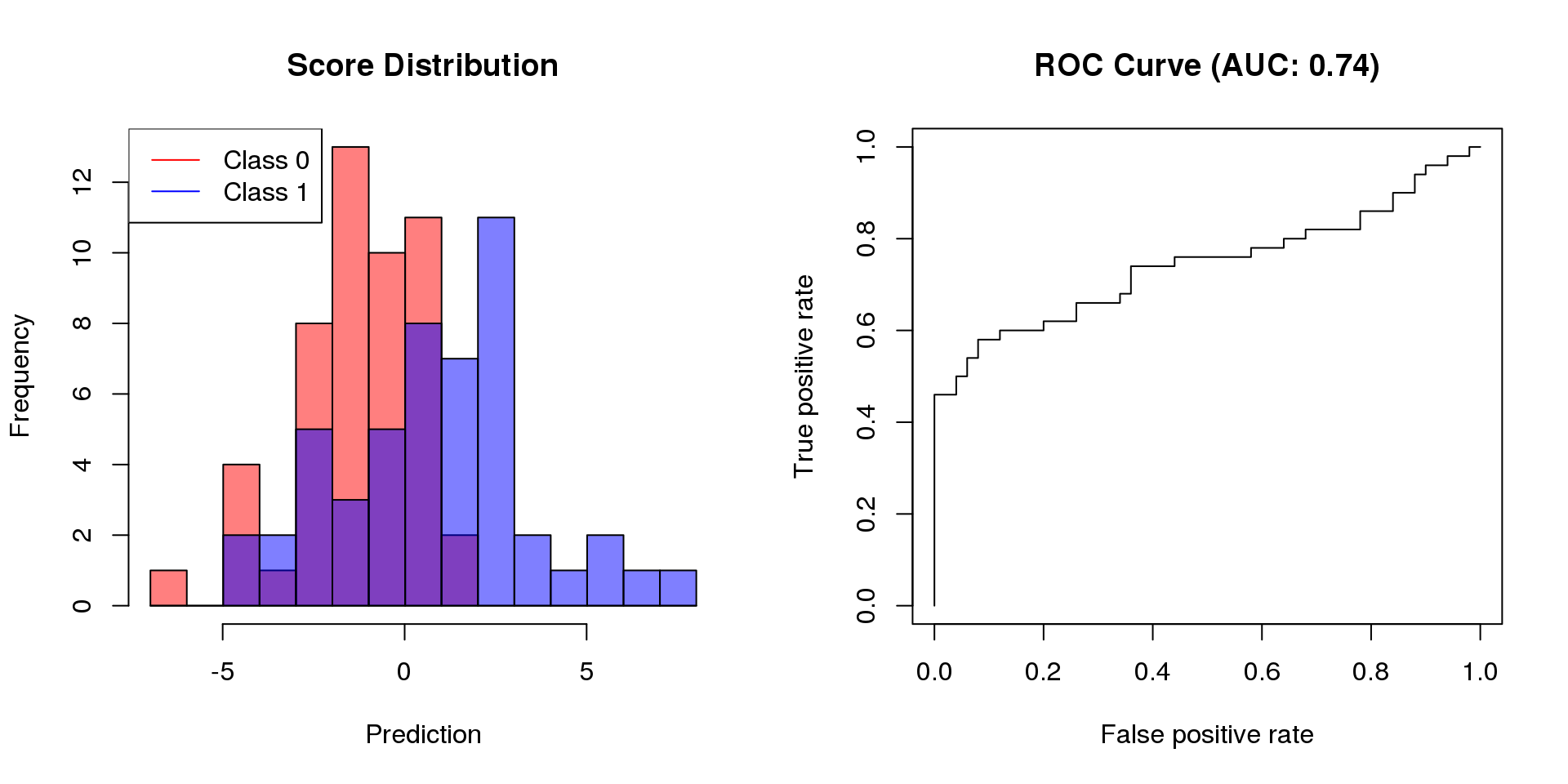
Receiver operating characteristic (ROC) curves are probably the most commonly used measure for evaluating the predictive performance of scoring classifiers.
The confusion matrix of a classifier that predicts a positive class (+1) and a negative class (-1) has the following structure:
Prediction/Reference Class +1 -1 +1 TP FP -1 FN TN Here, TP indicates the number of true positives (model predicts positive class correctly), FP indicates the number of false positives (model incorrectly predicts positive class), FN indicates the number of false negatives (model incorrectly predicts negative class), and TN indicates the number of true negatives (model correctly predicts negative class).
For classification problems, classifier performance is typically defined according to the confusion matrix associated with the classifier. Based on the entries of the matrix, it is possible to compute sensitivity (recall), specificity, and precision. For a single cutoff, these quantities lead to balanced accuracy (sensitivity and specificity) or to the F1-score (recall and precision). For evaluate a scoring classifier at multiple cutoffs, these quantities can be used to determine the area under the ROC curve (AUC) or the area under the precision-recall curve (AUCPR).
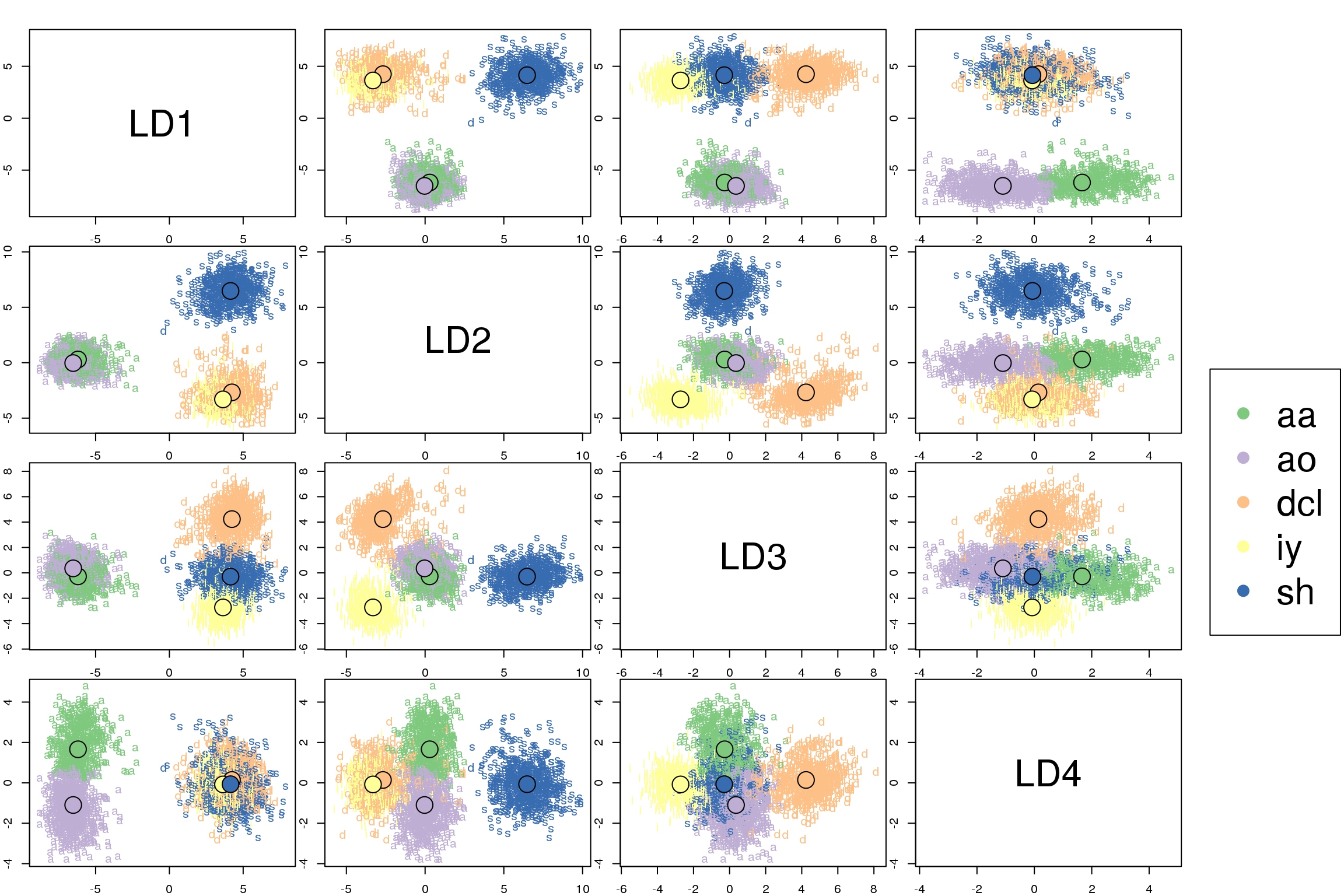
Discriminant analysis encompasses methods that can be used for both classification and dimensionality reduction. Linear discriminant analysis (LDA) is particularly popular because it is both a classifier and a dimensionality reduction technique. Quadratic discriminant analysis (QDA) is a variant of LDA that allows for non-linear separation of data. Finally, regularized discriminant analysis (RDA) is a compromise between LDA and QDA.
This post focuses mostly on LDA and explores its use as a classification and visualization technique, both in theory and in practice.
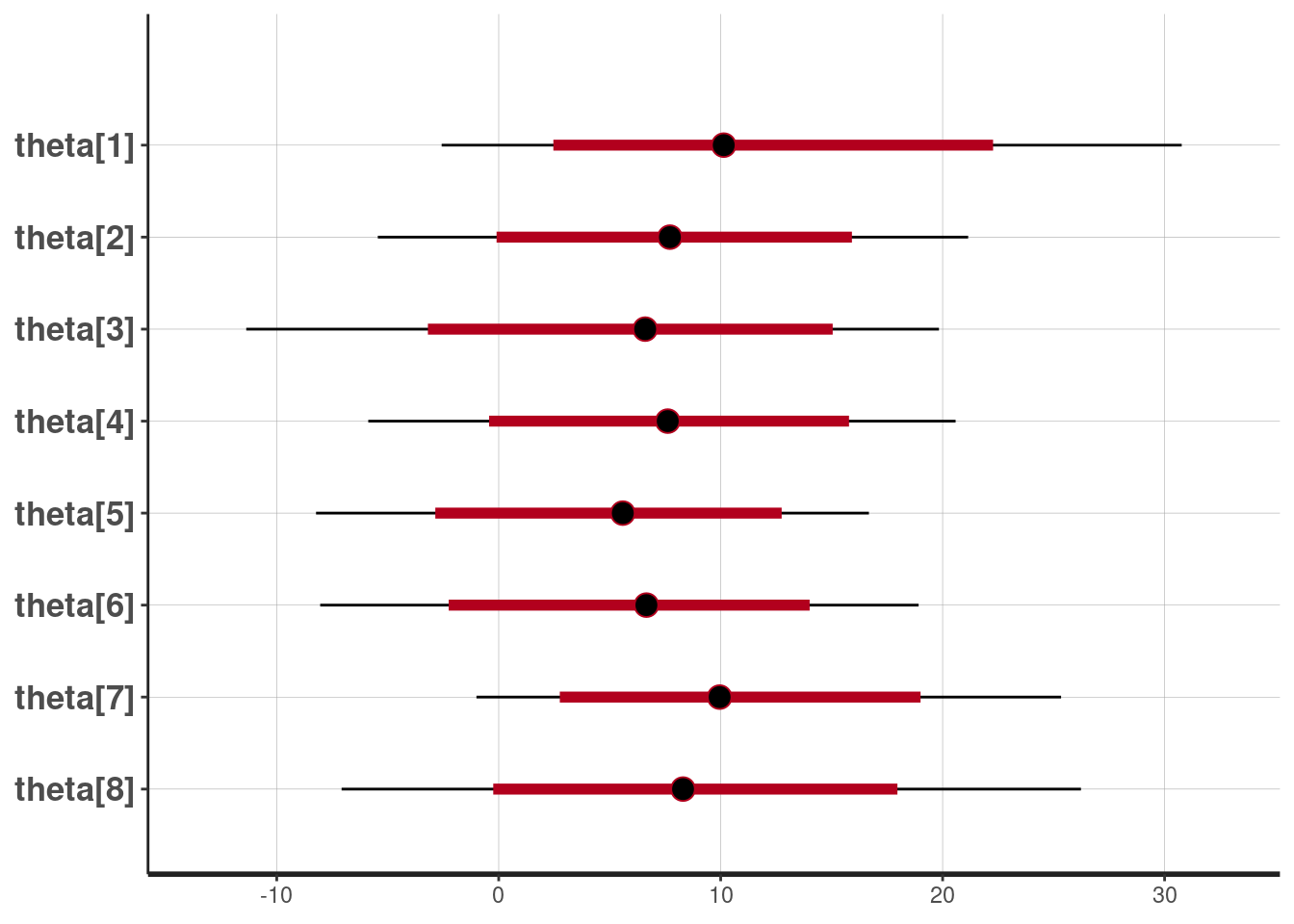
Probabilistic programming enables us to implement statistical models without having to worry about the technical details. It is particularly useful for Bayesian models that are based on MCMC sampling. In this article, I investigate how Stan can be used through its implementation in R, RStan. This post is largely based on the GitHub documentation of Rstan and its vignette.
Introduction to Stan Stan is a C++ library for Bayesian inference.
In a recent post, I have discussed performance measures for model selection. This time, I write about a related topic: performance measures that are suitable for selecting models when performing feature selection. Since feature selection is concerned with reducing the number of dependent variables, suitable performance measures evaluate the trade-off between the number of features, \(p\), and the fit of the model.
Performance measures for regression Mean squared error (MSE) and \(R^2\) are unsuited for comparing models during feature selection.
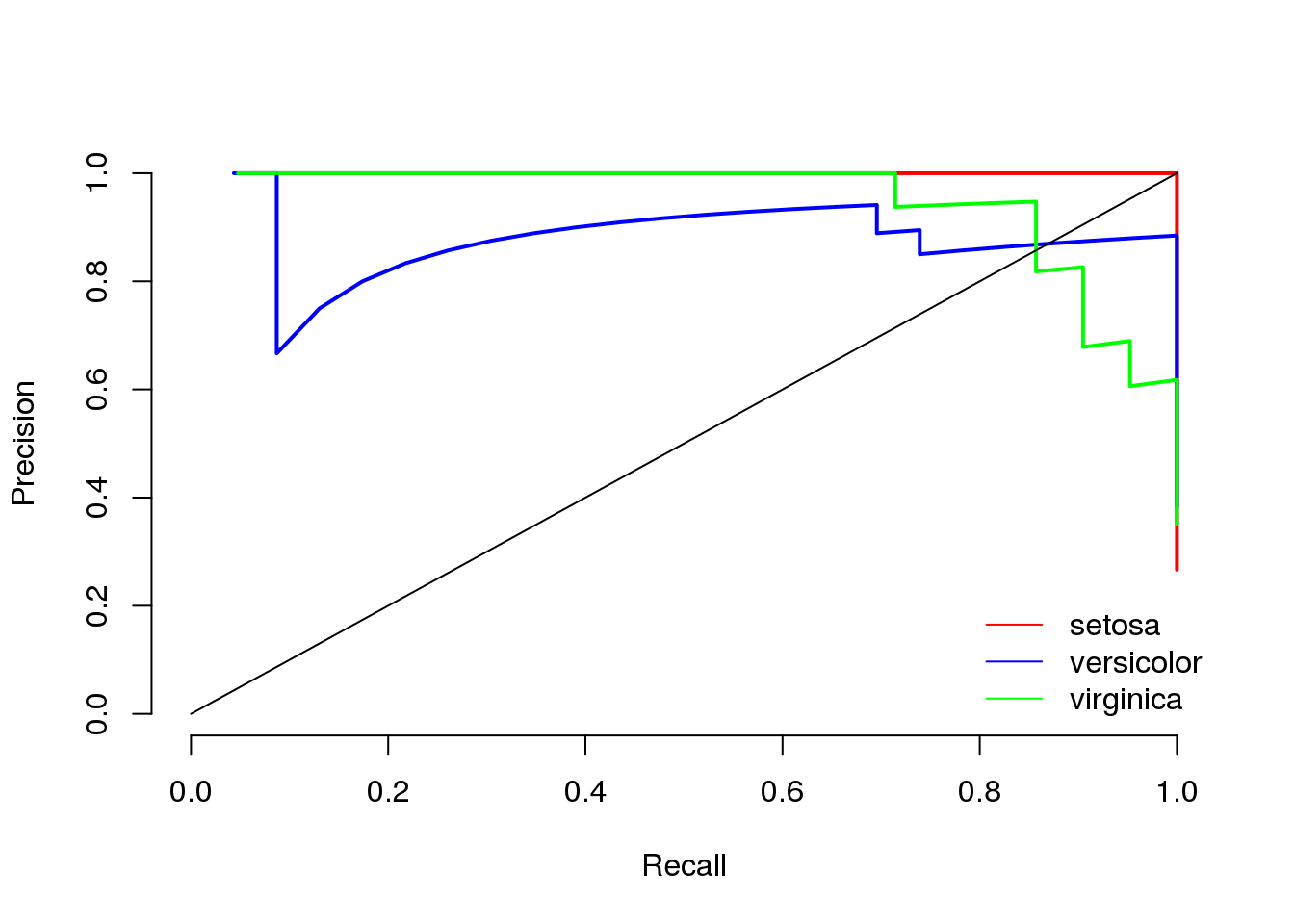
Recently, I have introduced sensitivity and specificity as performance measures for model selection. Besides these measures, there is also the notion of recall and precision. Precision and recall originate from information retrieval but are also used in machine learning settings. However, the use of precision and recall can be problematic in some situations. In this post, I discuss the shortcomings of recall and precision and show why sensitivity and specificity are generally more useful.
There are several performance measures for describing the quality of a machine learning model. However, the question is, which is the right measure for which problem? Here, I discuss the most important performance measures for selecting regression and classification models. Note that the performance measures introduced here should not be used for feature selection as they do not take model complexity into account.
Performance measures for regression For models that are based on the same set of features, RMSE and \(R^2\) are typically used for model selection.